

Kubernetes从部署到运维详解
发布时间:2018-02-09 浏览:711打印字号:大中小
Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。Kubernetes在模型建立之初就考虑了容器跨机连接的要求,支持多种网络解决方案,同时在Service层次构建集群范围的SDN网络。其目的是将服务发现和负载均衡放置到容器可达的范围,这种透明的方式便利了各个服务间的通信,并为微服务架构的实践提供了平台基础。而在Pod层次上,作为Kubernetes可操作的最小对象,其特征更是对微服务架构的原生支持。
架构及部署
Architecture
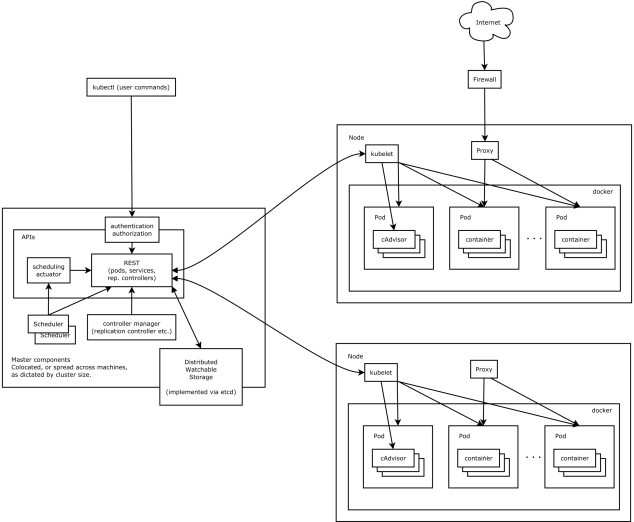
Kubernetes是2014年6月开源的,采用Golang的语言开发,每一个组件互相之间使用的是Master API的方式,Kubernetes的架构模式是用Master-slave模式,并且支持多种联机网络,支持多种分布式存储架构。
Master的核心组件是API server,对外提供REST API服务接口。kubernetes所有的信息都存储在分布式系统ETCD中. Scheduler是kubernetes的调度器,用于调度集群的主机资源。Controller用于管理节点注册以及容器的副本个数等控制功能。
在Node上的核心组件是kubelet,它是任务执行者,会跟apiserver进行交互,获取资源调度信息。 kubelet会根据资源和任务的信息和调度状态与Docker去交互,调用Docker的API, 创建、删除与管理容器,而kube-Proxy可以根据从API里获取的信息以及整体的Pod架构状态组成虚拟NAT网络。
快速部署过程
在最新更新的kubernetes 1.4版本中,社区开发了专用的部署组件kubeadm, 用来完成kubernetes集群整体的部署过程。Kubeadm是对以往手动或脚本部署的简化,集成了manifest配置、参数设置、认证设置、集群网络部署以及安全证书的获取。需要注意的是kubeadm目前默认从gcr.io的镜像中心获取镜像,若需使用其他镜像源,需要更改源码编译出定制版本。
Ubuntu 16.04环境的使用过程如下: 设定部署主机资源

1)在所有节点上(包括master和node)部署基础运行环境
部署内容包括docker, kubelet, kubeadm, kubectl kubernetes-cni 运行如下命令:# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
# cat <
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
# apt-get update
# apt-get install -y docker.io kubelet kubeadm kubectl kubernetes-cni
2)部署Master
在Master上运行 kubeadm init, 运行结束后,可获得集群的token,以及提示在node上运行的命令:
3)添加节点
在master上的kubeadm init的输出中获取相应的参数并在Node上运行:
4)部署网络
kubernete集群需要可以跨主机的网络解决方案,使得位于不同主机的pod可以相互通信。目前有多种类似的解决方案,例如weave network, calico 或者 Canal。当前使用的是weave net
关于网络,对于隔离要求较高的场景需求,采用calico是比较合适的选择。calico会帮助容器在主机间搭建纯二层的网络,在每个主机上维护一个路由表,用来获取目标容器所在主机的可达路径,以及本机容器的路有项。利用iptables的防火墙机制去做隔离。容器之间跨主机进行交互时,IP包从容器出发,经过本地路有表选路,通过目标网段所在主机的路有项,到达目标主机,然后在目标主机内,进入路有选路前,先经由iptables隔离规则(可设置)进行判断决定是否丢弃或返回,然后再经路有选路到目标容器,最终到达目标容器。整个过程没有任何封包解包的过程,传输效率较高。
隔离规则可以设定在同一用户名下的哪些容器可以被隔离成一组,被隔离的容器间可通信,而与其它容器不可通信。或者设置规则来组成更加丰富的隔离效果。
部署组件详解
在kubernetes 1.4版本利用kubeadm部署过程中,安装的插件包括kube-discovery,kube-proxy和kube-dns,分别负责部署阶段配置的分发, NAT网络和集群系统的dns服务。值得注意的是kube-proxy不再通过manifest来运行,是通过插件用demonset的方式来部署。
1)kubeadm
在kubeadm init运行阶段,首先创建验证token以及静态pod文件(manifest的文件),以及运行所需的证书和kubeconfig。完成这些工作后,kubeadm会等待apiserver的启动并正常运行,以及等待首个节点的接入。
由于master节点启动kubelet来运行manifest文件,并且在kubelet.conf中设置了需要连接当前主机为master,因此此master 也会作为node节点接入,并且master作为节点运行也为kube-discovery提供运行的必须环境。
当节点加入并且apiserver运行正常后,将标示master的角色,kubeadm.alpha.kubernetes.io/role=master。
2)Kube-discovery
随后在部署运行kube-discovery时,在kube-discovery所运行的pod上设置node的亲和性,并将它限制成为必须在master上运行的pod。由于kube-discovery的主要功能是证书及token等配置的管理与分发,并且后续的节点加入时只需要一个简单的master ip信息,因此将kube-discovery限制到了master节点运行,以此统一服务的入口。 这些通过在pod的annotations来实现 requiredDuringSchedulingIgnoredDuringExecution表示在调度过程中需要满足的条件,和后面的nodeSelectorTerms在一起类似于nodeselector。这样设置即可将pod限制到master主机中。
3)Kube-dns
从kubernetes 1.3开始,kube-dns已经不再使用etcd+skydns+kube2sky的方式。而是使用了dns缓存及转发工具dnsmasq,以及利用skydns库和本地内存缓存组合而成的kube-dns。
Kube-dns将从kubernetes master中监听变动的service和endpoint信息,并建立从service ip 到service name的域名映射(对于无service的,将会建立pod ip和相应域名的映射)。Kube-dns将这些信息存放在本地的内存缓冲中,并监听127.0.0.1:10053提供服务。
Dnsmasq是简单的域名服务、缓存和转发工具,这里利用它的转发功能将kube-dns的dns服务转接到外部,参数–server=127.0.0.1:10053。
二.运维管理
租户资源管理Namespace(命名空间)
namespace 是kubernete用来做租户管理的对象。每个租户独享自己的逻辑空间,包括replication controller、 pod、 service、 deployment、configmap等。 常用的查看方式:
kubectl get
或查看所有namespace的某类资源
kubectl get
例如:查看所有的pod,并希望看到所部署的节点位置
kubectl get pod –all-namespaces –o wide
查看namespace为 test的replication controller,以及labet
kubectl get rc –namespace=test –show-labels
配置管理ConfigMap
当服务运行在容器中时,需要访问外部的变量,或者需要根据环境的不同更改配置文件,比如,DB以传统的方式运行在容器云之外,当服务启动时,需要初始化包含DB信息的配置文件。当需要切换db时,就需要更改配置文件, 当容器中有服务在运行时, 并不推荐登陆到容器内进行文件配置更改。
合理的方式是利用kubernetes的配置管理,将配置信息写入到ConfigMap, 并挂载到对应的pod中。
例如golang程序golang-sample需要访问配置文件db.json,内容如下:
{"dbType": "mysql",
"host": "192.168.1.22",
"user": "tenxcloud",
"password": "password",
"port": "3306",
"connectionLimit": 200,
"connectTimeout": 20000,
"database": "sample"
}
将db.json写入config.yaml中:
apiVersion: v1
data:
db.json: |-
{
"dbType": "mysql",
"host": "192.168.1.22",
"user": "tenxcloud",
"password": "password",
"port": "3306",
"connectionLimit": 200,
"connectTimeout": 20000,
"database": "sample"
}
kind: ConfigMap
metadata:
name: config-sample
namespace: sample
创建configmap对象:
kubectl create –f config.yaml
在 pod中添加对应的volume
apiVersion: v1
kind: Pod
metadata:
labels:
name: golang-sample
name: golang-sample
namespace: sample
spec:
containers:
- image: inde.tenxcloud.com/sample/golang-sample:latest
volumeMounts:
- mountPath: /usr/src/app/config/db/
name: configmap-1
volumes:
- configMap:
items:
- key: db.json
path: db.json
name: config-sample
name: configmap-1
当pod创建运行后,服务在pod容器内只需要读取固定位置的配置文件, 当配置需要改变时, 更新ConfigMap并重新分发到pod内,这样重启容器后,容器内所挂载的配置也会相应更新。当需要pod容器同时使用一个ConfigMap 时,更新ConfigMap内容的同时,可以批量更新容器的配置。
主机运维管理
对于运维操作来说,kubectl是一个很便利的命令行工具,首先可以对各种资源进行操作,比如添加、获取、删除,通过更多命令参数得到指定的信息。
获取资源列表及详细信息的方式可通过kubectl get 来进行,具体的操作运行kubectl get –help即可。
实践使用过程中,对节点的运维操作会影响到应用的使用和资源的调度,比如由于配置升级需要对节点主机进行重启,需要考虑已经运行在其上的容器的状况,用户的希望是对资源池的操作尽量少的影响容器应用,同时资源池的变动和上层的容器服务解藕。
当需要对主机进行维护升级时,首先将节点主机设置成不可调度模式:
kubectl cordon[nodeid]然后需要将主机上正在运行的容器驱赶到其它可用节点:
kubectl drain [nodeid]
当容器迁移完毕后,运维人员可以对该主机进行操作,配置升级性能参数调优等等。当对主机的维护操作完毕后, 再将主机设置成可调度模式:
kubectl uncordon [nodeid]
这样新创建的容器即可以分配到该主机,可以通过kubectl patch 对资源对象进行实时修改,比如为service增加端口,为pod修改容器镜像版本。Annotation 可以帮助用户更好的设置kubernete自定义插件。用户可以在自建组件中获取资源中对应的annotation以此进行操作。通过kubectl label可以方便的对资源打标签,比如对node打标签,然后容器调度时可指定分配到对应标签的主机。
Kubernetes作为容器集群管理工具,为应用平台提供了基于云原生的微服务支持,其活跃的社区吸引了广大开发者的热情关注,刺激了容器周边生态的快速发展,同时为众多互联网企业采用容器集群架构升级内部IT平台设施,构建高效大规模计算体系提供了技术基础。
(原文来自CSDN)

